

Have you ever wondered…,
How does IBM i manage complex, high-precision calculations while conserving storage space?
The answer lies in….,
The arcane art of packed data types, a mystery we’re about to decode.
Introduction
In computing, data comes in every form and size, and managing it efficiently is the key to success. The “packed” data type is one of the more enigmatic data types on IBM i. Packed data types are essential for various tasks, such as high-precision calculations, data storage, and data transmission.
This is because each byte of storage, except for the low-order byte, can contain two decimal numbers. The leftmost byte of a low-order byte contains a digit, and the rightmost byte holds the sign (positive or negative). As part of this blog, we will unravel the mystery of packed data types on IBM i, exploring what they are, how they work, and why they are important.
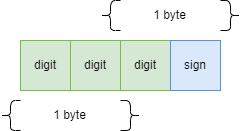
A positive number is represented with Hexadecimal F, while a negative number is represented by Hexadecimal D.
Let’s say,
In the signed packed numbers, +123456 and -123456 are represented as X’0123456F’ and X’0123456D’, respectively.
Here’s what 123456 looks like in unsigned packed format: X’123456′
The packed data format for number 123 consumes two bytes of storage and is stored as follows:
| 1 | 2 | 3 | +ve sign |
| 0001 | 0010 | 0011 | 1111 |
2 bytes
To find the length in digits of a packed-decimal field, use the formula below:
Number of digits = 2n – 1.
Where n = number of packed input record positions used(bytes).
In the case of an x-digit packed field, the amount of storage N (in bytes) required is as follows:
| N = (x/2) + 1 | signed packed |
| N = (x/2) + 1 | unsigned packed, x odd |
| N = x/2 | unsigned packed, x even |
Usage of Packed Data Concept in Reverse Engineering
To extract values from a string field, decoding the values stored in packed data type fields is as follows:
Step 1: The length of actual data it could hold is determined by the formula [(x/2) + 1] – odd field length or [(x/2)] – even field length, where x is the total field length.
Step 2: In hexadecimal, you must take care of the zeroes and sign digits
Step 3: Divide it by 10 to the power of decimal places to obtain a number with decimal places.
The SQL query will look like this:

Here is a code snippet that illustrates the use case scenario:
TESTPF is the DDS source of a PF.
TSTRGDTA is the source of the SQLRPGLE program.
TESTPFJ is the outfile where the data set is stored as a string.



The SQLRPGLE shows how to extract appropriate data from a string data set.
As shown in the below snippet, the data in the database file TESTPF is as follows:

Using the SQLRPGLE program, we insert data into TESTPFJ from the file TESTPF. This is what the data looks like:

The program can be checked in debug mode. Variable valInsert holds the value of a SQL query formed at runtime from TESTPFJ that is inserted into a table from it. The selection of columns in the SQL query formed in VALINSERT results in a segregated structure forming the column set in the TESTPF file.
Below is an example of the segregated data (using the query built-in runtime in the SQLRPGLE program):
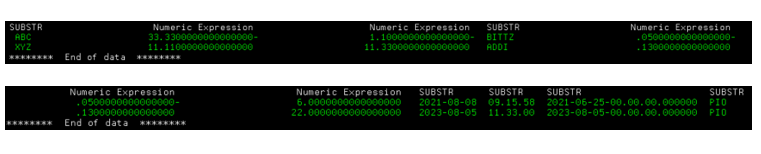
Depending on your needs, you can play around with the logic and adapt it to meet your requirements.
This logic could help users extract packed data from sting data sets that are still using a lower version of IBM i OS in which the EXTRACT table function is not available in SQL.
Conclusion
Packed data types on the IBM i platform may appear mysterious at first, but they are a testament to the platform’s efficiency and versatility. These unique data types provide a powerful way to store and manipulate numeric data with precision and minimal storage overhead.
So, the next time you encounter a packed data type within your IBM i system, remember that it’s not merely a string of ones and zeros but a testament to the ingenuity of data management—an elegant solution to the perpetual challenge of balancing precision and efficiency. Embracing the mysteries of packed data types allows us to unlock their full potential and ensure that our calculations are not just numbers but precise reflections of reality.


")